
Doğal Dil İşleme (NLP) Teknolojisine Detaylı Bir Bakış
NLP (Natural Language Processing), Türkçe ismiyle Doğal Dil İşleme (DDİ), günümüzde bir çok alanda farklı amaçlar ile kullanılmaktadır.

Doğal Dil işleme Projeleri, müşteri geri bildirim analizi, çağrı kalitesi ölçümü, müşteri hizmetlerinin otomatikleştirmesi ve müşterinin sesi operasyonlarının iyileştirilmesi gibi birçok alanda uygulanabilir. Ayni zamanda müşteri memnuniyeti sağlamak, operasyonel verimliliği yükseltme ve rekabet avantajı elde etmeyi de sağlayabilir.
Bu yazımızda Doğal Dil İşleme (NLP) teknolojisinin tüm detaylarını paylaşacağız, Doğal Dil işleme analiz yöntemleri ve Doğal Dil İşleme örneklerini keşfedeceğiz.
Doğal Dil İşleme (NLP) Nedir?
Doğal Dil İşleme (DDİ), yapay zekânın bir alt dalıdır. Amacı, insanların kullandığı doğal dilin analiz edilerek anlaşılabilmesi ve çıktılara dönüştürülebilmesidir. Bu alanda metin analitiği ve araştırma yapılır. Kısacası, insanlar ve doğal dili çözümleyen bilgisayarlar arasındaki ilişkiyi anlamlandıran bir yapay zekâ fonksiyonudur.
Dilbilimcilerin dilin yapısını ve kurallarını açıklamak için geliştirdikleri teoriler, yapay zeka doğal dil işleme’nin dildeki desenleri tanımasına ve işlemesine yardımcı olur. Aynı şekilde, NLP’nin gelişimi, dil bilimindeki keşiflere dayalı olarak dilin işlenmesi ve anlaşılması için yeni yaklaşımların geliştirilmesine katkıda bulunur.

Doğal Dil İşleme (NLP) Teknikleri
Doğal dil işleme, bilgisayarların metinleri daha iyi anlamasına yardımcı olmak için iki temel tekniği kullanır: sözdizimsel analiz ve anlamsal analiz.
Sözdizimsel analiz, cümle yapısını belirler ve kelime ilişkilerini incelerken anlamsal analiz, metnin anlamını çözmeye odaklanır ve kelime anlamlarını araştırır.
Sözdizimsel Analiz
Sözdizimsel analiz ya da ayrıştırma, cümle yapısını, kelimelerin düzenlenme biçimini ve kelimeler arasındaki ilişkiyi belirlemek için dilbilgisi kurallarını kullanarak metni inceler. Bu analizin bazı görevleri arasında sembolizasyon, konuşma etiketlemesi, lemmatizasyon ve kökten türetme bulunur.
Konuşmayı Yazıya Dönüştürme (Speech2text)
Speech2text, es kaydı olarak elde edilen bir ifadenin yazılı biçime dönüştürülmesidir. Yazıya dönüştürme algoritmalarında NLP alanının desteği sinyal işleme algoritmalarının tespit ettiği sesleri dil modeli üzerinde işleyerek en seslerle oluşturulabilecek en olası kelime ve cümleleri oluşturmaktır.

Dil Tespiti (Language Detection)
Bir metnin hangi dilde yazılmış olduğunun otomatik tespit edilmesidir. Bu işlemin yapılabilmesi için yaygın kullanılan çeşitli yöntemlerden bazıları alttaki gibidir:
- Dil biliminin çıkarımsadığı dil kuralları kullanılarak metnin hangi dil olduğunun kural tabanlı bir sistemle belirlenmesi
- Bir dile ait çok sayıda veriden oluşan bir veritabanında ngram analizi yapılarak test edilecek veride geçen kelime ve kelime gruplarının bu dilde kullanılanlarla uyumunun ölçülerek skorlanması
- Doğal dil işleme algoritmaları yardımıyla her dil bir sınıf olacak şekilde eğitilen modellerin kullanımı
- Ngram analizi, bir metin içinde art arda gelen kelimeler veya harfer dizisinin sıklıklarını dikkate alarak genellikle metin içinde hangi örüntülerin sıklıkla geçtiğini belirlemek için yapılan analizlerde kullanılır.
Cümle Bölümleme (Sentence Segmentation)
Paragraf veya daha büyük bir bütün olarak bulunan metni cümlelere veya kullanım alanına göre fikir belirten daha küçük bölgelere (opinion unit) ayırma işidir.
Bu konuda yapılan çalışmalar başlangıçta kural tabanlı olarak, noktalama ve büyük harf kullanımı, söz dizimi yapısına uyum gibi analizlerle çözümler üretmiştir. Fakat bu yöntemler özellikle günümüzde git gide artan kuralsız sosyal medya, müşteri yorumu gibi verilerde yüksek başarı sağlayamamıştır.
Daha güncel çalışmalar daha çok güdümlü makine öğrenmesi yöntemleri ve dil modelleri ile cümleyi anlamsal olarak bölmeye önem veren derin öğrenme modelleri ile yapılmaktadır.
Küçük Harfe Dönüştürme (Lowercase Converter)
Büyük harf kullanımının önemli olmadığı durumlarda kelimelerin ortak olmasını daha rahat yakalayabilmek için tüm harfleri küçük harfe çevirir. En basit işlemlerden olan bu adımda bile dil parametresine dikkat edilmezse beklenmedik hatalar çıkabilir.

Terimlere Ayırma (Tokenization)
Metni kullanım amacına göre işlenebilir birimlere böler. Bu bölümler bazen kelimeler, bazen cümleler bazen de paragraflar veya tam ters yönde heceler vs olabilir. Kullanım alanlarının çoğunda anlam kelimelerin kullanımı ile belirlendiği için kelimeler terim olarak kullanılmaktadır.
Kelimelere ayırma işlemi yapılırken yine ilgili göreve göre birleşik kelimelerin ayrılması, alfanumerik olmayan karakterlerin dahil edilmesi gibi durumlarda göreve özel karar verilmesi gerekebilir.
Gereksiz Kelime Ayıklama (Stopwords Removal)
Yapılacak analizlerde bir katkı sağlamayan ve çok sık geçtiği için analizlerde öne çıkan kelimelerin ayıklanması işlemidir. (ör: ve, ama, bir, şey…)
Bu kelimelerin ayıklanması özellikle veri içinde kelime bazlı bilgi çıkarılması gerektiği durumlarda önemlidir.
Gereksiz kelimelerin ayıklanmadan analizlere dahil edilmesi durumunda Ngram analizlerinde özellikle gereksiz kelimelerin araya gelmesinden dolayı Ngramların sıklıkları doğru bir şekilde ölçülemeyebilir.
Veya kelimelerin sadece varlıkları ile öğrenen modellerde konu ile ilgisi olmayan gereksiz kelimelerin metne eklenmesi atanacak sınıfı beklenmedik şekilde değiştirebilir.
İstenmeyen Örüntü Ayıklama (Unwanted Pattern)
Metnin kaynağına veya içeriğine bağlı olarak ortaya çıkıp metinlere anlamsal katkı sağlamayan örüntülerin ayıklanması işlemidir. (web sitesi linkleri, twitter etiketleri, hex karakterler vb.)
Özellikle internet sitelerinden otomatik olarak çekilen verilerde istenmeyen karakterler sıklıkla karşılaşılan bir durumdur.
Bu verilerin ayıklanması sürecinde genellikle belirli örüntüleri yakalayan kurallar oluşturmakla beraber terimlerin sıklıkları ve anlamasal analizleri yapılarak bu örüntülerin tespitinin de otomatikleştirildiği algoritmalar kullanımdadır.
Cümle Ögelerini Belirleme (Part of Speech Tagging)
Cümle içindeki kelime veya kelime gruplarının cümlenin hangi öğesine hangi görevle bağlı olduğu bilgisi ile etiketlenmesidir. Bu işlem için dil içindeki söz dizimi kuralları kullanılabildiği dil modelleri veya kelime vektörlerinin yardımıyla eğitilen güdümlü öğrenme algoritmaları da sıklıkla bu işlem için kullanılmaktadır.
Anlamsal Analiz
Anlamsal analiz, metnin anlamını çözmeye odaklanır. İlk olarak, her kelimenin anlamını inceler (sözcüksel anlam bilimi). Daha sonra, kelimelerin bir araya gelmesinin ve bağlam içinde ne anlama geldiğinin araştırılmasına geçer. Anlamsal analizin temel alt görevleri arasında kelime anlamındaki belirsizliğin giderilmesi ve ilişki çıkarımı yer alır.
Yazım Düzeltme (Spelling Correction)
Yazım hatalarının otomatik olarak tespit edilip düzeltilmesidir. Bu düzenlemelerde genellikle benzerlik algoritmaları ve dil modelleri kullanılmaktadır.
Dil modelleri (Language Models) bir dilin yapay bir görev ile derin öğrenme methodlarıyla eğitilerek dil içindeki kelime, kelime grubu ve cümlelerin akışının makineye öğretilmesiyle oluşan hazır modellerdir. Bu modeller genellikle bir sonraki kelimenin veya bir sonraki cümlenin tahmin edilmesi veya cümle içinde maskelenmiş verilerin tahmin edilmesi gibi görevler ile eğitilir.
Bu görevlerle yapılan eğitimlerde sistem görevi başarıyla tamamlamak için tüm kelime ve cümleler arasındaki bağlantıları kendince anlamış olmalıdır. Bu yapı oluşturulduktan sonra pek çok NLP görevinde yardımcı olarak rol alabilir.
Yazım düzeltme algoritmalarında da dil modelleri o zamana kadar gelen kelimelere göre bir sonraki muhtemel kelime için öneriler oluşturabilir. Ve bu öneriler içinden benzerlik algoritmasıyla hatalı yazıma en benzer olan öneri kullanılabilir.
Karakter Düzeltme (Declassification)
Türkçe karakter kullanılmadan yazılmış ifadelerdeki bu karakterlerin doğru Türkçe versiyonları ile değiştirilmesidir. Bu işlem yapılırken Türkçe’nin yapısal özelliklerinden faydalanılmaktadır.
Dilimizde bulunan en temelleri küçük ünlü uyumu, benzeşme vb. Olan yapısal kurallara uyum kontrol edilerek karakterlerde düzenleme yapılması en genel yöntemdir. Bu kurallara ek olarak metnin akışının da dikkate alınmasıyla yazım düzeltme gibi daha genel kullanımlı algoritmalar ortaya çıkmaktadır.
Kelime Anlam Çözümlemesi (Word Sense Disambiguation)
Metinde kullanılan kelimelerin olası anlamları arasında doğru anlamın seçilmesi işlemidir. Bu işlemin sağlıklı işletilebilmesi için kullanılacak algoritmada sağlam bir dil modeli bulunması önemlidir.
Alternatif olarak söz dizimleri ile de kelime tipine göre seçim yapan algoritmalar bulunmakla beraber genel başarıları dil modeli kullanan sistemlere göre zayıf kalmaktadır. Örnek: Yüz verdik tepemize çıktılar. Numaram beş yüz on. Sporcuyu daha hızlı yüzsün diye yüreklendirmeye çalıştılar.
Mesela yukarıdaki metinlerde yüz kelimesi farklı anlamlarda kullanılmıştır. Bu anlamların birbirinden ayrılması kelime anlam çözümlemesinin konusudur.
Özdeşik Çözümleme (Coreference Resolution)
Bir metinde aynı varlığa veya kavrama referans yapan tüm ifadelerin belirlenmesi ve ilişkilendirilmesi işlemidir. Bu teknik, metnin anlamını daha iyi anlamak ve doğru bir şekilde yorumlamak için kullanılır. Özellikle makine çevirisi, metin özetleme veya bilgi çıkarma gibi doğal dil işleme uygulamalarında önemli bir rol oynar.

Morfolojik Analiz (Morphological Analysis)
Kelimeleri tipine göre (isim, fiil, sıfat vb) sınıflandırarak cümledeki olası kullanım görevinin tespitine yardımcı olur. Bu bilgi özellikle varlık tanıma gibi kelimenin tipi ile yakından ilgili olan uygulamalarda çok önemlidir.
Bu analiz için mevcut pek çok kural tabanlı sistem vardır. Bu sistemler dil üzerindeki söz dizimi kurallarına ek olarak dile ait sözlüklerden de faydalanarak kelimeleri gruplandırabilmektedir.
Gövdeleme (Lemmatization)
Gövdeleme (Lemmatization), bir kelimenin çeşitli çekim ekleriyle farklı formlara bürünmüş halini en geniş kök haline dönüştürme işlemidir. Bu işlem sırasında yapım ekleri çıkarılır, ancak anlamı değiştiren ekler korunur.

Köke İndirgeme (Stemming)
Köke İndirgeme (Stemming) ise kelimenin çekim ve yapım eklerini tamamen çıkararak aynı anlamı taşıyan kelimelerin en küçük ortak köklerine indirgeme işlemidir. Bu yöntemde, kelimenin kökü oluşturan ortak öğeler tespit edilir ve bu öğeler diğer kelimelerden çıkarılarak temel kök elde edilir.
Normalizasyon (Text Normalization)
Metin içinde aynı anlamı paylaşan fakat cümle içindeki durumuna bağlı olarak farklı çekim ve yapım eki almış kelimelerin kullanım alanına göre ortaklaştırılmasını sağlayan adımlardır.
Burada verilerin ortaklaştırılması, veri seyrekliği (data sparsity) nedeniyle algoritmaların veriyi yeterince gruplayıp anlamlandıramadığı durumlarda uygulandığında oldukça faydalı olmaktadır.
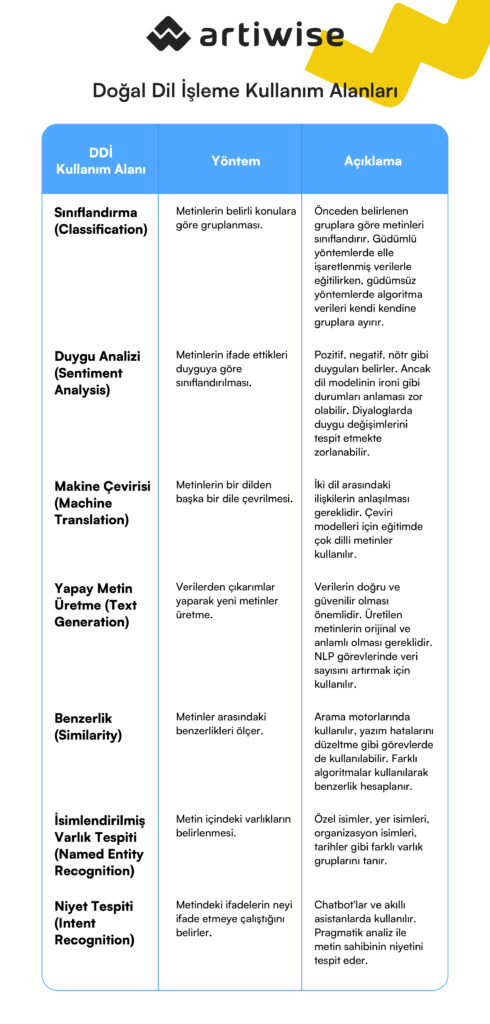
Doğal Dil İşleme Kullanım Alanları
Doğal dil işleme, metin analizi, duygu analizi, otomatik çeviri gibi şekilde kullanılırken, arama motorları, sosyal medya analizi, dil öğrenme uygulamaları gibi birçok alanda da karşımıza çıkabilir. Bu teknoloji şirketlere müşteri memnuniyeti ve müşteri sadakati artırma konusunda büyük bir avantaj sağlar.

Artiwise’ın Doğal Dil İşleme ve Duygu Analizi Yetenekleri ile Müşteri Deneyimini İyileştirin!
Artiwise Müşterinin Sesi (VoC) Platformu, geleneksel anket tabanlı yöntemlerin ötesine geçerek müşteri geri bildirimlerini DDİ ve duygu analizi teknikleriyle işler.
Bu da şirketlerin, müşteri algı ve duygularını kök neden analizi çıktıları üzerinden anlamasını sağlar. Platformun sektöre özel sunduğu analiz ve yapay zeka temelli aksiyon öneri modelleri ile kullanıcılar müşteri deneyimini radikal bir şekilde geliştirebilirler.

Kolay entegrasyon ve güvenlik önlemleriyle desteklenen platform, şirketlere hızlı ve verimli bir şekilde müşteri memnuniyetini artırma fırsatı da sunar. Artiwise ile müşteri içgörüsü ve bildirimlerini değerlendirin ve şirketinizi rekabetin önünde tutun.
1 haftalık ücretsiz POC hizmetimizden yararlanmak ve müşteri deneyimi operasyonlarınızdaki fırsat ve tehditleri keşfetmek için bizimle iletişime geçin!


